Ch3 Structured APIs¶
Disclaimer: The content on this page is created purely from personal study and self-learning. It is intended as personal notes and reflections, not as professional advice. There is no commercial purpose, financial gain, or endorsement intended. While I strive for accuracy, the information may contain errors or outdated details. Please use the content at your own discretion and verify with authoritative sources when needed.

When errors are detected using the Structured APIs
At the core of the Spark SQL engine are the Catalyst Optimizer and Project Tungsten. Together, these support the high-level DataFrame and Dataset APIs and SQL queries.
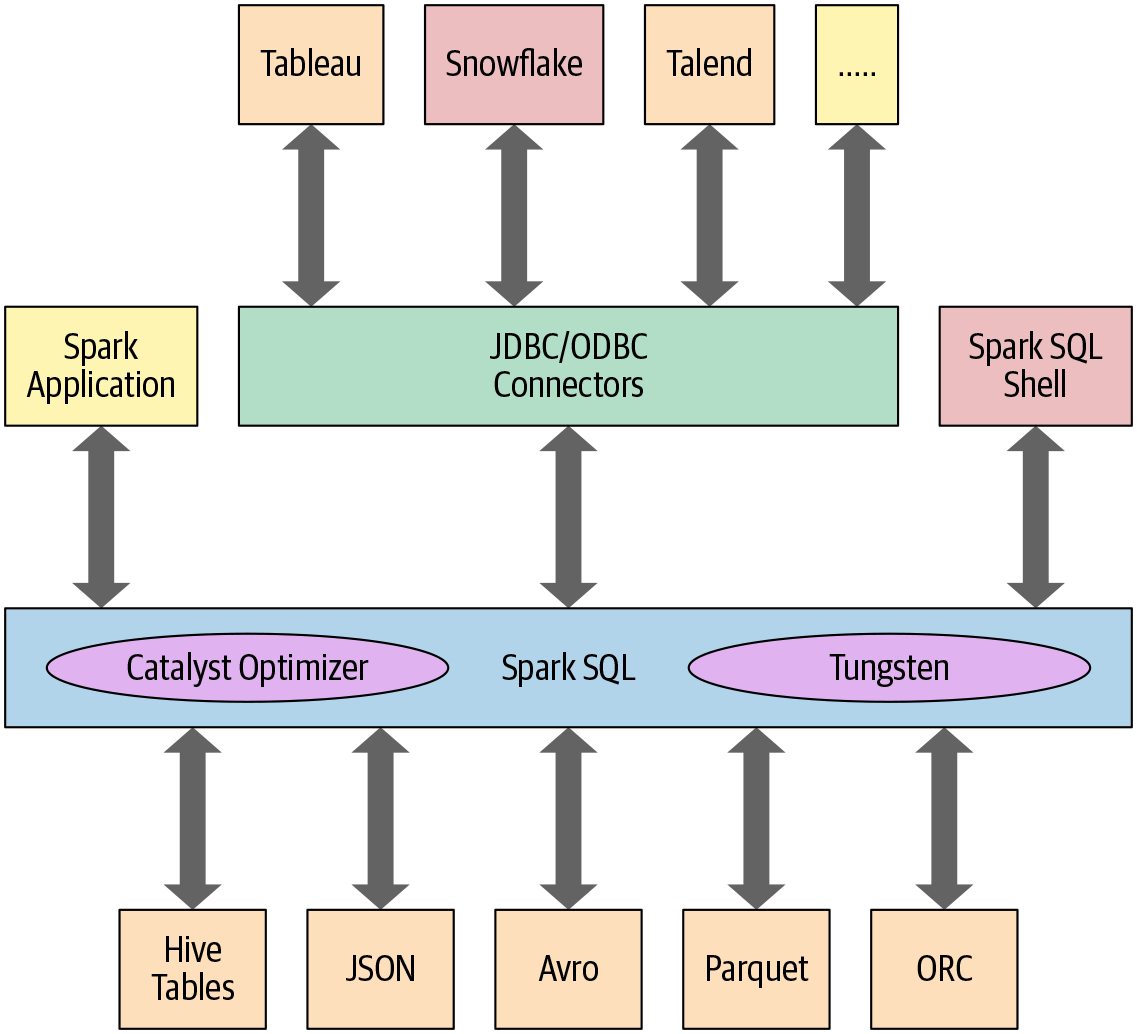
Spark SQL and its stack
The Catalyst Optimizer takes a computational query and converts it into an execution plan. It goes through four transformational phases:
- Analysis
- any columns or table names will be resolved by consulting an internal Catalog
- Logical Optimization
- Applying a standard-rule based optimization approach
- the Catalyst optimizer will first construct a set of multiple plans and then
- using its cost-based optimizer (CBO), assign costs to each plan.
- These plans are laid out as operator trees
- Physical Planning
- Code Generation
- The final phase of query optimization involves generating efficient Java bytecode to run on each machine.
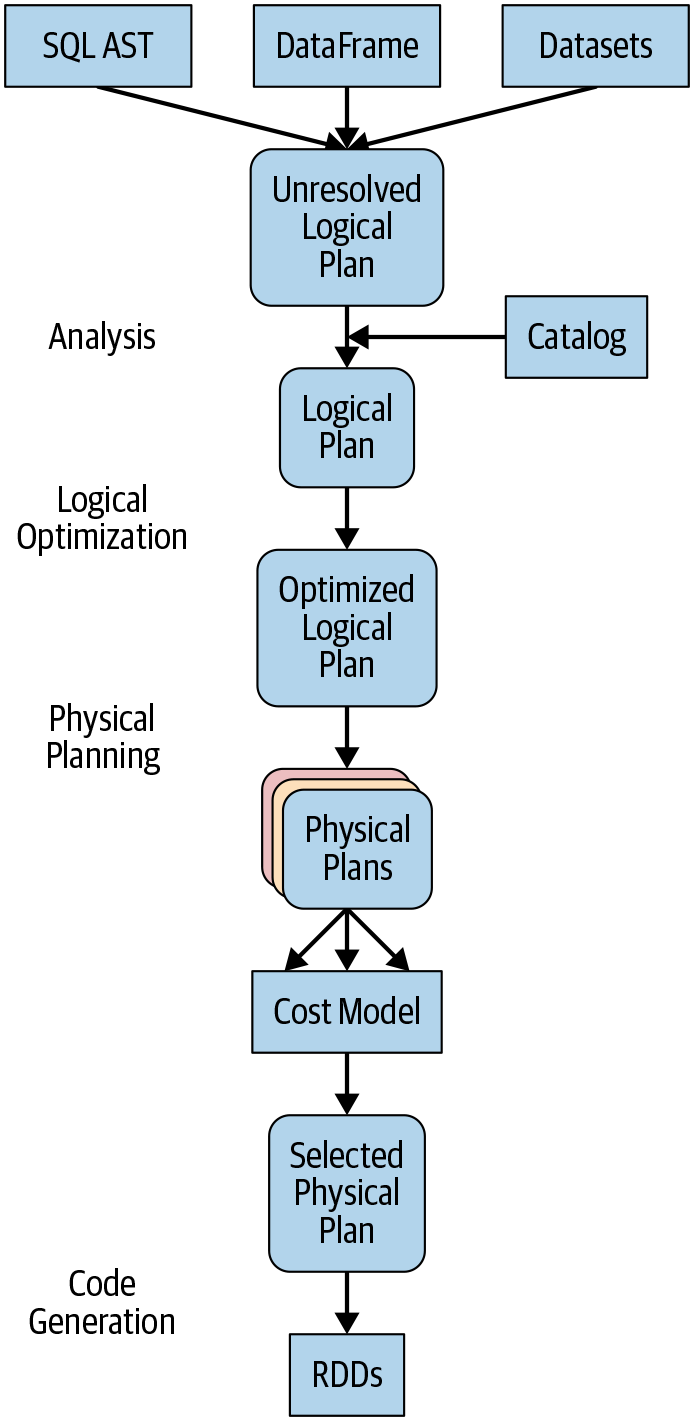
A Spark computation's four-phase journey
Real Example:
// In Scala
// Users DataFrame read from a Parquet table
val usersDF = ...
// Events DataFrame read from a Parquet table
val eventsDF = ...
// Join two DataFrames
val joinedDF = users
.join(events, users("id") === events("uid"))
.filter(events("date") > "2015-01-01")
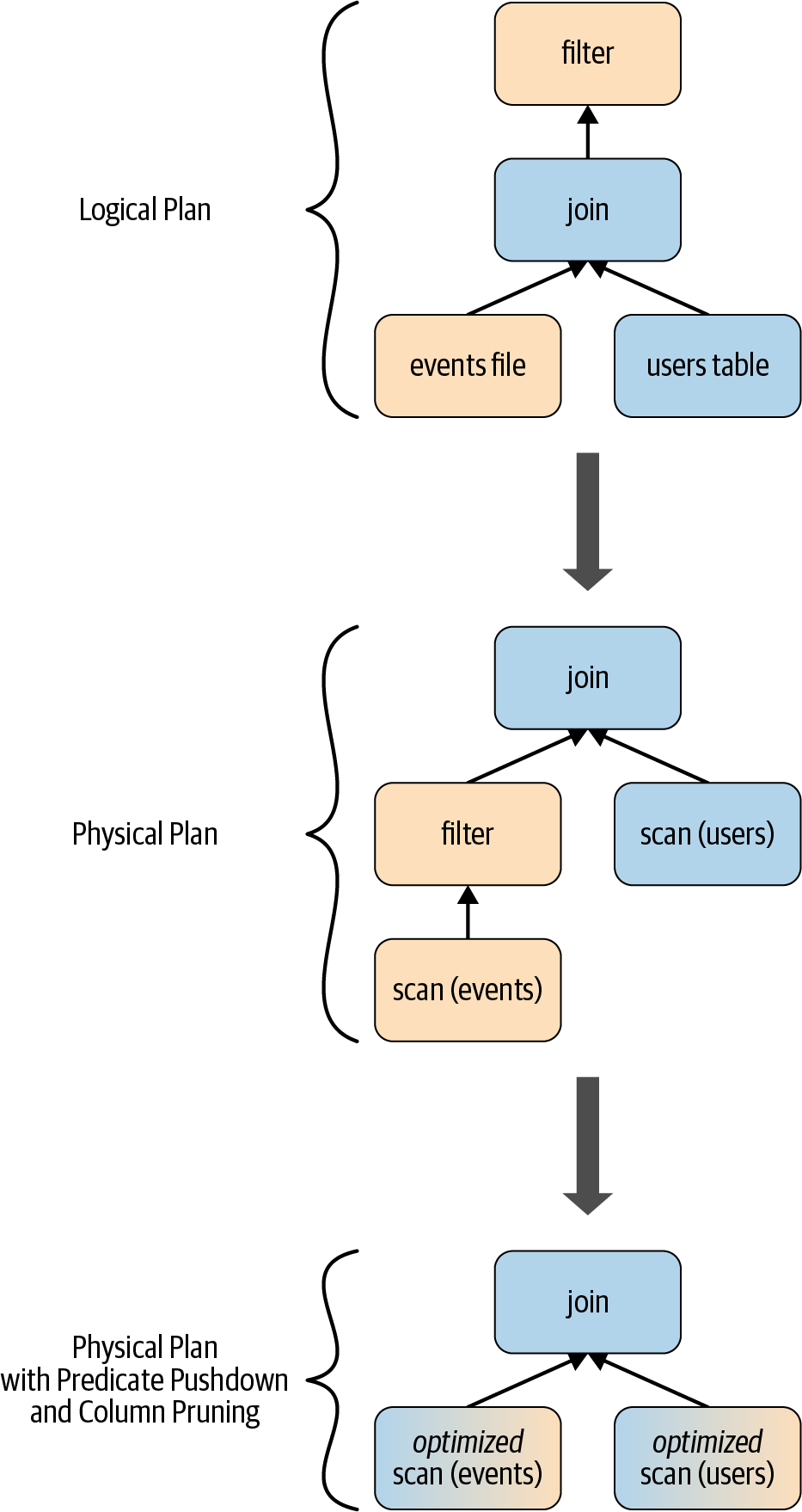
An example of a specific query transformation