Best Practices for Optimizing Apache Iceberg Workloads in AWS¶
General Best Practices¶
Tip
- Use Iceberg format version 2.
- Use the AWS Glue Data Catalog as your data catalog.
- Use the AWS Glue Data Catalog as lock manager.
- Use Zstandard (ZSTD) compression
Optimizing Storage¶
Tip
- Enable S3 Intelligent-Tiering
- Archive or delete historic snapshots
- Delete old snapshots:
expire_snapshots - Set retention policies for specific snapshots: use Historical Tags
- Archive old snapshots: S3 Tags + S3 Life cycle rules
- Delete old snapshots:
- Delete orphan files
remove_orphan_filesVACUUMstatement: equals toexpire_snapshots+remove_orphan_filesin Spark.
Historical Tags¶
to mark specific snapshots and define a retention policy for them.
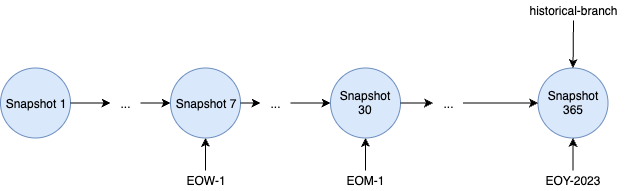
Historical Snapshot Tag
S3 Tags¶
spark.sql.catalog.my_catalog.s3.write.tags.my_key1=my_val1
spark.sql.catalog.my_catalog.s3.delete-enabled=false
spark.sql.catalog.my_catalog.s3.delete.tags.my_key=to_archive
spark.sql.catalog.my_catalog.s3.write.table-tag-enabled=true
spark.sql.catalog.my_catalog.s3.write.namespace-tag-enabled=true
VACUUM statement¶
CREATE TABLE my_table (
...
)
TBLPROPERTIES (
'vacuum_max_snapshot_age_seconds' = '432000', -- 5 days
'vacuum_min_snapshots_to_keep' = '1',
'vacuum_max_metadata_files_to_keep' = '100'
);
Optimizing Read Performance¶
Tip
- Partitioning
- Partition your data
- Identify columns that are frequently used in queries
- Choose a low cardinality partition column to avoid creating an excessive number of partitions
- Use Hidden Partitioning
- Use Partition Evolution
- Partition your data
- Tuning File Size
- Set target file size and row group size:
write.target-file-size-bytes,write.parquet.row-group-size-bytes,write.distribution-mode - Run regular compaction
- Set target file size and row group size:
- Optimize Column Statistics
write.metadata.metrics.max-inferred-column-defaults:100
- Choose the Right Update Strategy (CoR)
write.update.mode,write.delete.mode, andwrite.merge.modecan be set at the table level or independently on the application side.
- Use ZSTD Compression
write.<file_type>.compression-codec
- Set the Sort Order
ALTER TABLE ... WRITE ORDERED BYALTER TABLE ... WRITE DISTRIBUTED BY PARTITIONALTER TABLE prod.db.sample WRITE DISTRIBUTED BY PARTITION LOCALLY ORDERED BY category, id
- As a rule of thumb, "too many partitions" can be defined as a scenario where the data size in the majority of partitions is less than 2-5 times the value set by
target-file-size-bytes.
Optimizing Write Performance¶
Tip
- Set the Table Distribution Mode
write.distribution-mode:none,hash,range- Spark Structured Streaming applications → set
write.distribution-modetonone.
- Choose the Right Update Strategy (MoR)
- Choose the Right File Format
- Set
write-formatto Avro (row-based format) if write speed is important for your workload.
- Set
- By default, Iceberg's compaction doesn't merge delete files unless you change the default of the
delete-file-threshold propertyto a smaller value.
Maintaining Tables by Using Compaction¶
Common Compaction Properties¶
| Configuration | Default | Description |
|---|---|---|
max-concurrent-file-group-rewrites |
5 | Maximum number of file groups to be simultaneously rewritten |
partial-progress.enabled |
false | Enable committing groups of files prior to the entire rewrite completing |
partial-progress.max-commits |
10 | Maximum amount of commits that this rewrite is allowed to produce if partial progress is enabled |
rewrite-job-order |
None | Force the rewrite job order based on the value. Options are bytes-asc, bytes-desc, files-asc, and files-desc |
max-file-group-size-bytes |
100GB | Specifies the maximum amount of data that can be rewritten in a single file group |
min-file-size-bytes |
75% of target file size | Files under this threshold will be considered for rewriting regardless of any other criteria |
max-file-size-bytes |
180% of target file size | Files with sizes above this threshold will be considered for rewriting regardless of any other criteria |
min-input-files |
5 | Any file group exceeding this number of files will be rewritten regardless of other criteria |
delete-file-threshold |
2147483647 | Minimum number of deletes that needs to be associated with a data file for it to be considered for rewriting |
Example¶

Partitions & File Groups
- The Iceberg table consists of four partitions
- The Spark application creates a total of four file groups to process.
- A file group is an Iceberg abstraction that represents a collection of files that will be processed by a single Spark job. That is, the Spark application that runs compaction will create four Spark jobs to process the data.
- The partition labeled
month=01includes two file groups because it exceeds the maximum size constraint of 100 GB. - In contrast, the
month=02partition contains a single file group because it's under 100 GB. - The
month=03partition doesn't satisfy the default minimum input file requirement of five files. As a result, it won't be compacted. - Lastly, although the
month=04partition doesn't contain enough data to form a single file of the desired size, the files will be compacted because the partition includes more than five small files.