dbt¶
Domain Ownership¶

Pipelines¶

Concrete Example¶


Environments¶

Enabling Business-Friendly Access and Optimizing Access Control Through Customized dbt Project Configuration¶
Problem Statement¶
By default, dbt creates all datasets in a single GCP project. This behavior does not meet our requirements due to the following reasons:
- Insufficient IAM isolation: Managing all environments in one project increases the risk of permission misconfigurations.
- Resource conflicts: Other GCP services used in BigQuery may conflict across environments if they share the same project.
- Unfriendly table naming for downstream users: Final table names include technical prefixes like
fctordim, which may confuse non-technical users such as marketers or editors.
To address this, we customize dbt's behavior to:
- Isolate each environment in its own GCP project.
- Assign datasets by domain in staging and production.
- Simplify final table names for easier consumption.
Data Sink¶
All raw data ingested through tools such as Airbyte, Fivetran, or custom data pipelines is initially landed in the sink project.
Datasets in this project are source-oriented, organized by their origin. For example, food_ga4, app_store, google_play etc.
This separation provides a clear boundary between raw source data and downstream transformations.
Staging Environment¶
- The GCP project used is the
stgproject. - All models are deployed in datasets by domain (e.g.,
news,food,fashion, etc.) - Model names retain their original names, such as
stg_*,int_*,fct_*,dim_*. - All models are configured to expire after a certain duration to reduce storage costs.
Production Environment¶
- The GCP project used is the
prodproject. - Final models (data products) are deployed in datasets by domain (e.g.,
news,food,fashion, etc.). All its upstream models are deployed in thehiddendataset in the same project in order to encapsulate the implementation details. - Model names are simplified to aliases only, without technical prefixes, to make them more user-friendly for non-technical stakeholders (e.g., articles, app_installs, fb_summary_daily).
Implementation Summary¶
- Customize macros
- Use
if elsecondition withtarget.nameindbt_project.ymlto dynamically configure settings based on the environment.
Cost Optimization¶
- Partitioned tables
- Incremental model with
insert_overwritestrategy: generates amergestatement that replaces entire partitions in the destination table.- Static partition
{% set partitions_to_replace = [ 'timestamp(current_date)', 'timestamp(date_sub(current_date, interval 1 day))' ] %} {{ config( materialized = 'incremental', incremental_strategy = 'insert_overwrite', partition_by = { 'field': 'event_time', 'data_type': 'timestamp', "granularity": "day" }, partitions = partitions_to_replace ) }} with events as ( select * from {{ref('events')}} {% if is_incremental() %} -- recalculate yesterday + today where timestamp_trunc(event_timestamp, day) in ({{ partitions_to_replace | join(',') }}) {% endif %} ), ... rest of model ... on_schema_change:append_new_columns
- Static partition
- Materialized model as
tableif the model is accessed multiple times in the downstream models, to avoid recomputing the same data repeatedly.
Data Mesh¶
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
- Data Mesh Principles and Logical Architecture
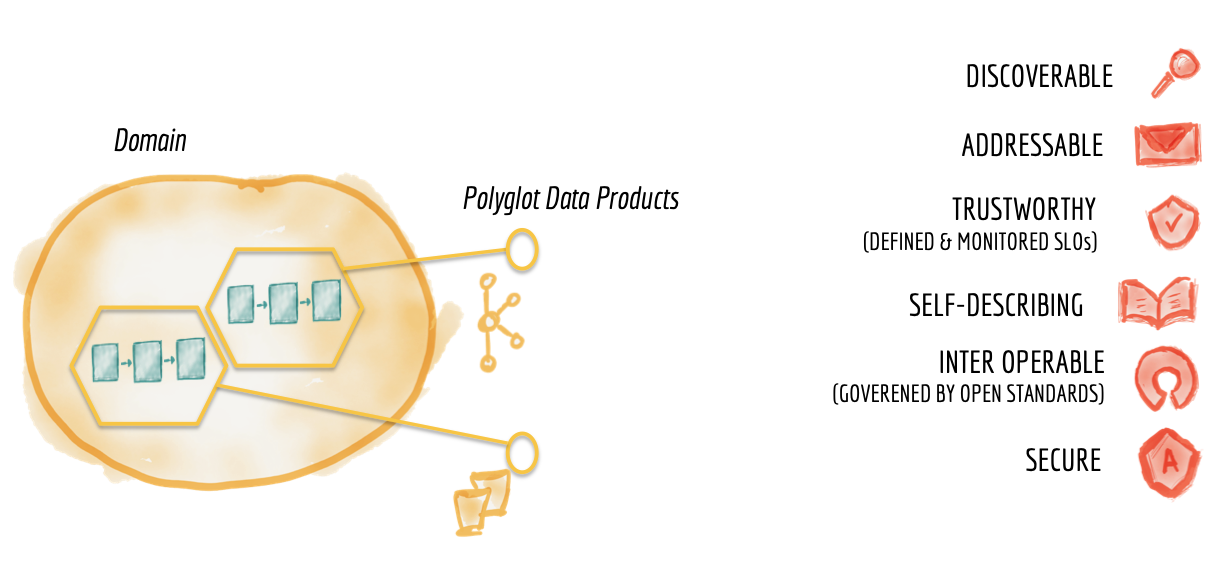
4 Key Principles:

Domain-oriented Decentralized Data Ownership

- From Medallion to DDD architecture
- CODEOWNERS
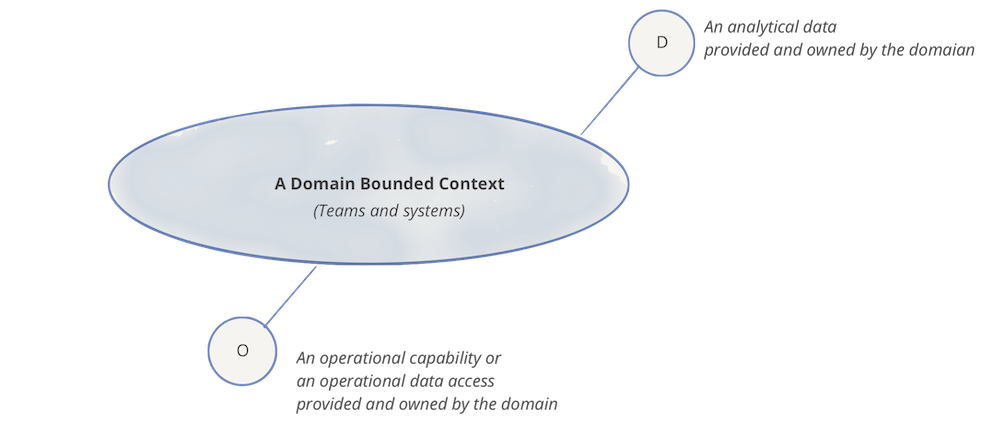
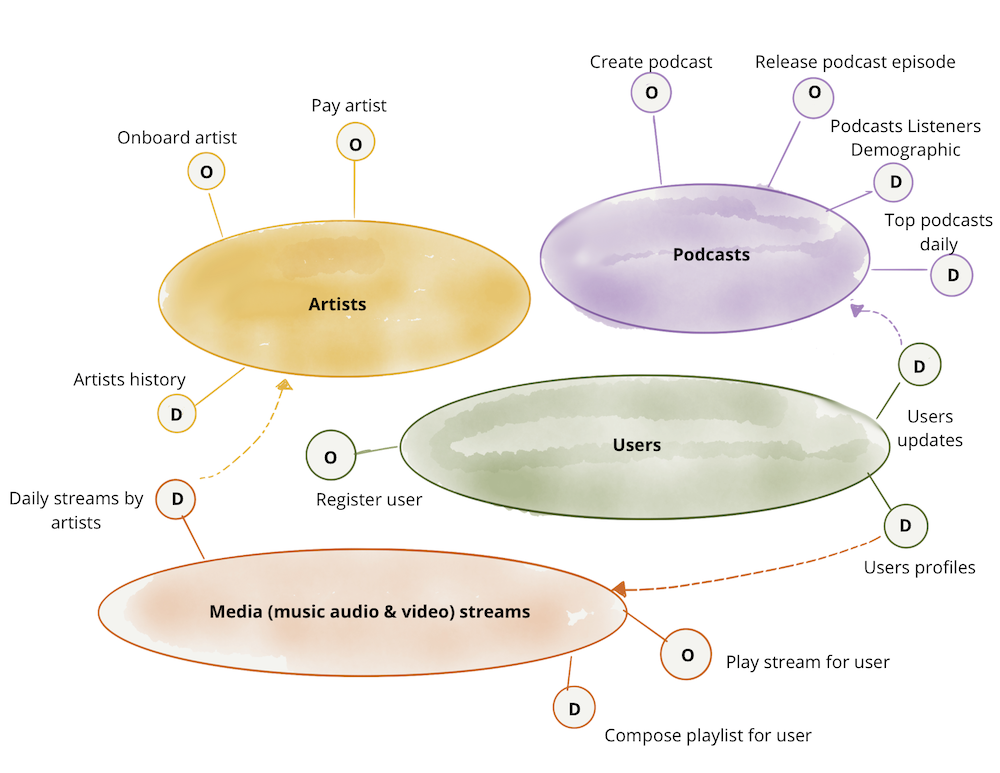
Data Products