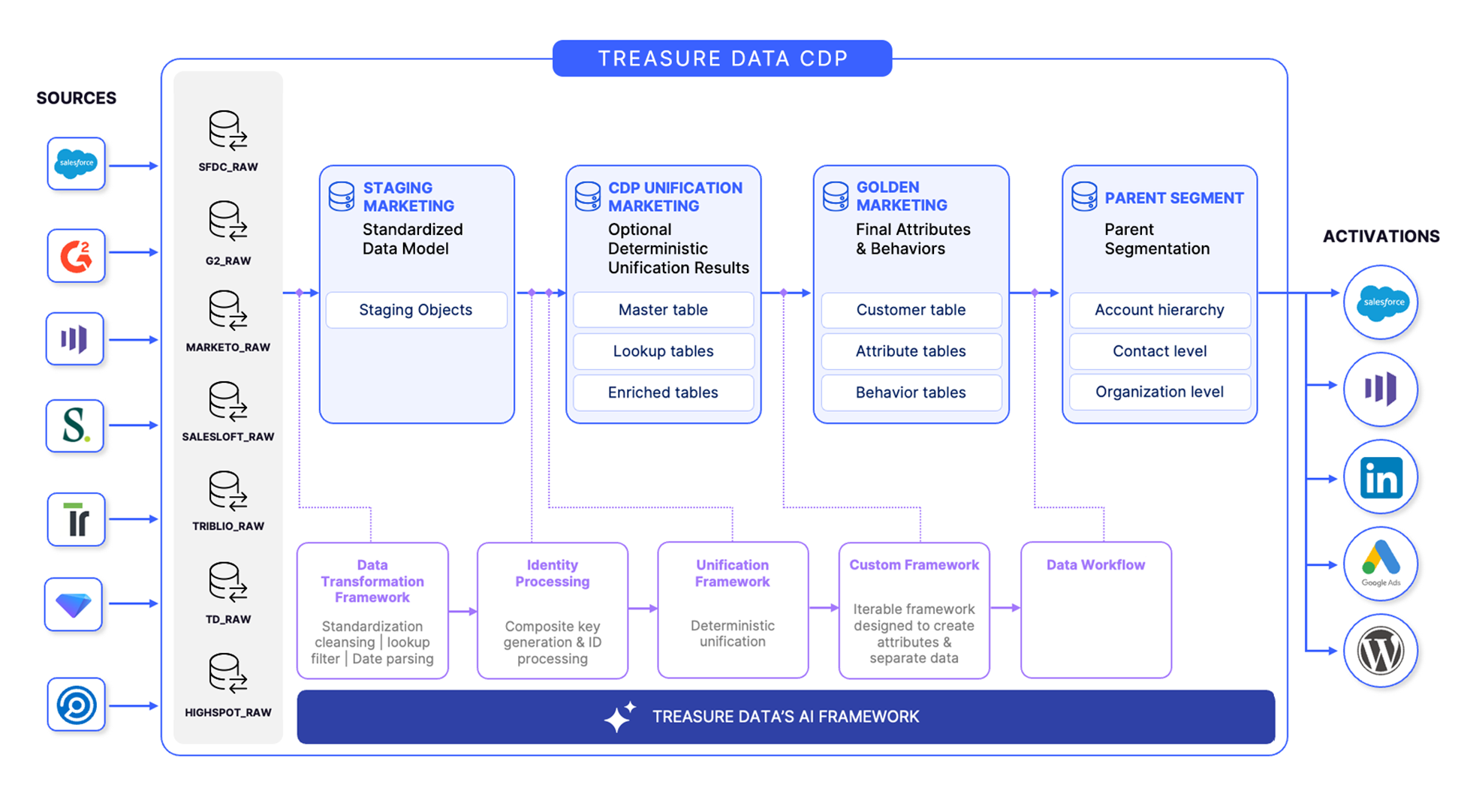
Treasure Data¶
Metrics¶
In 2023, Treasure Data currently serves over 700 accounts and more than 6,000 users. Since 2022, platform usage has doubled. Each day, the system handles 2.5 million+ Trino queries and over 100,000 Hive queries. It processes more than 200 trillion rows daily and performs over 10 billion S3 GET requests per day to read partition data from AWS S3.
Overview¶
 How Treasure Data reduced ad spend and increased marketing ROI by 20%
How Treasure Data reduced ad spend and increased marketing ROI by 20%
 Treasure Data Enterprise Customer Data Platform | Demo
Treasure Data Enterprise Customer Data Platform | Demo
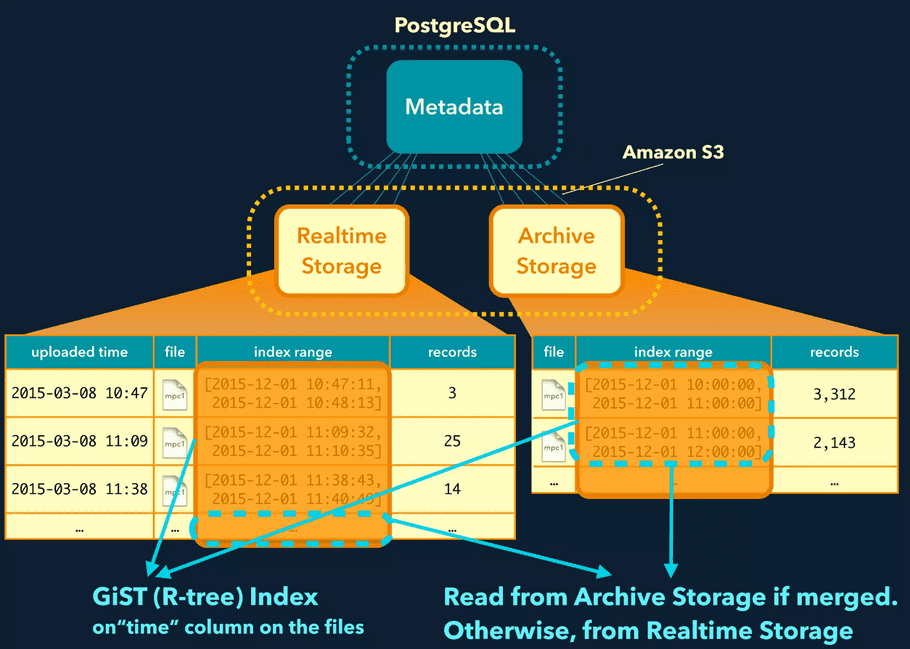
Tech Stack¶
- Wvlet, similar to BigQuery's pipe query syntax
- Trino
- Hive 4 (Hive 4.0.x comes with Iceberg 1.4.3 included.)
- Plazma (Closed Source)
- PostgreSQL (metadata)
- S3
- Real-time Storage
- Archive Storage
- fluentd
- embulk: Data Connector and Result Export
 LinkedIn Post
LinkedIn Post
Data Architecture¶
 Data Architecture 2021 (Source: Secure exchange SQL - Treasure Data at Trino Summit 2023)
Data Architecture 2021 (Source: Secure exchange SQL - Treasure Data at Trino Summit 2023)
 Data Architecture 2023 (Source: Secure exchange SQL - Treasure Data at Trino Summit 2023)
Data Architecture 2023 (Source: Secure exchange SQL - Treasure Data at Trino Summit 2023)
 Pros and Cons (Source: What is Treasure Data CDP?)
Pros and Cons (Source: What is Treasure Data CDP?)
 Zero-Copy Integrations Between Your CDP and Data Warehouse
Zero-Copy Integrations Between Your CDP and Data Warehouse
Data Ingestion¶
Questions¶
- Data Lakehouse Architecture? proprietary (MPC1)
- How to deal with dbt Core? (dbt Fusion)
- SQLMesh
Amazon S3 Parquet Export Integration Amazon Elastic MapReduce Integration

https://www.linkedin.com/in/pramodmanjappa/