Ch7 Optimizing and Tuning Spark Applications¶
Disclaimer: The content on this page is created purely from personal study and self-learning. It is intended as personal notes and reflections, not as professional advice. There is no commercial purpose, financial gain, or endorsement intended. While I strive for accuracy, the information may contain errors or outdated details. Please use the content at your own discretion and verify with authoritative sources when needed.
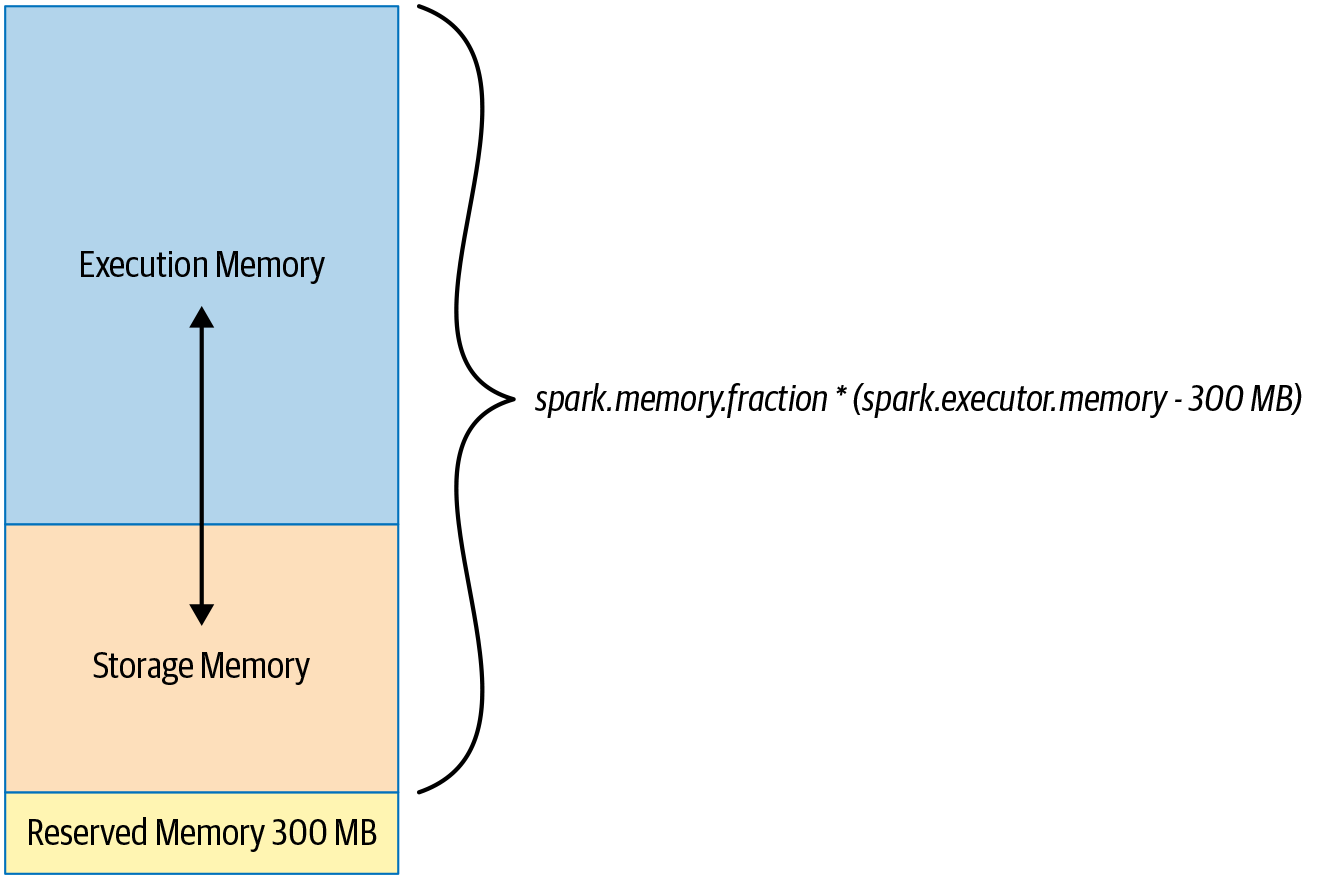
Executor Memory Layout
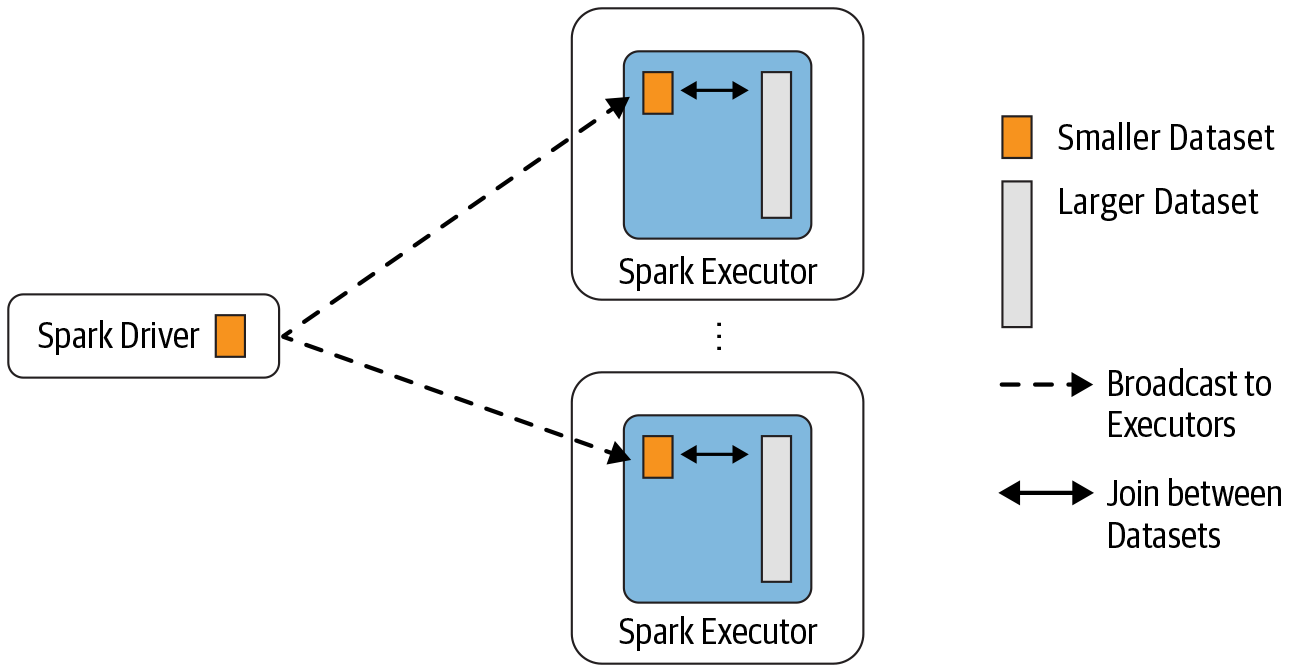
Broadcast Hash Join
- Optimizing and Tuning for Efficiency
- Viewing and Setting Apache Spark Configurations
- 3 ways to specify Spark configurations
- configuration files
- spark-submit conf
- programmatically interface via the spark shell
- 3 ways to specify Spark configurations
- Scaling Spark for Large Workloads
- dynamic resouce allocation
- executors' memory
- executors' shuffle service
- maximizing spark parallelism
spark.sql.shuffle.partitions200 by default, reduce
- Viewing and Setting Apache Spark Configurations
-
Caching and Persistence of Data
- DataFrame.cache()
- DataFrame.persist()
MEMORY_ONLYMEMORY_ONLY_SERMEMORY_AND_DISKMEMORY_AND_DISK_SERDISK_ONLYOFF_HEAP
- When to Cache and Persist
- Iterative ML training
- DataFrames accessed commonly
- When not to Cache and Persist
- Too big to fit in memory
-
A Family of Spark Joins
- Broadcast Joins
- Shuffle Sort-Merge Joins
- When each key within two large data sets can be sorted and hashed to the same partition by Spark
- When you want to perform only equi-joins to combine two data sets based on matching sorted keys
- When you want to prevent Exchange and Sort operations to save large shuffles across the network
-
Inspecting the Spark UI