Ch1 & 2 Introduction to Spark¶
Disclaimer: The content on this page is created purely from personal study and self-learning. It is intended as personal notes and reflections, not as professional advice. There is no commercial purpose, financial gain, or endorsement intended. While I strive for accuracy, the information may contain errors or outdated details. Please use the content at your own discretion and verify with authoritative sources when needed.
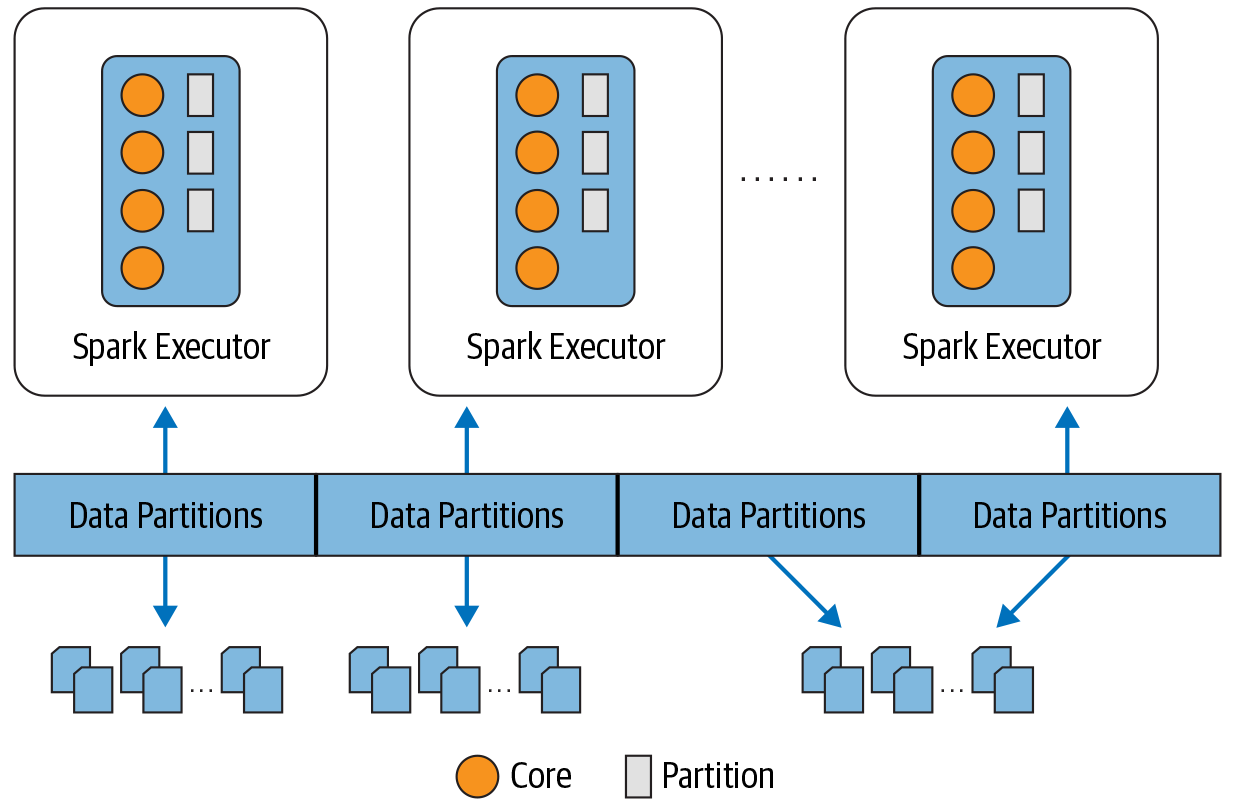
Each executor's core gets a partition of data to work on
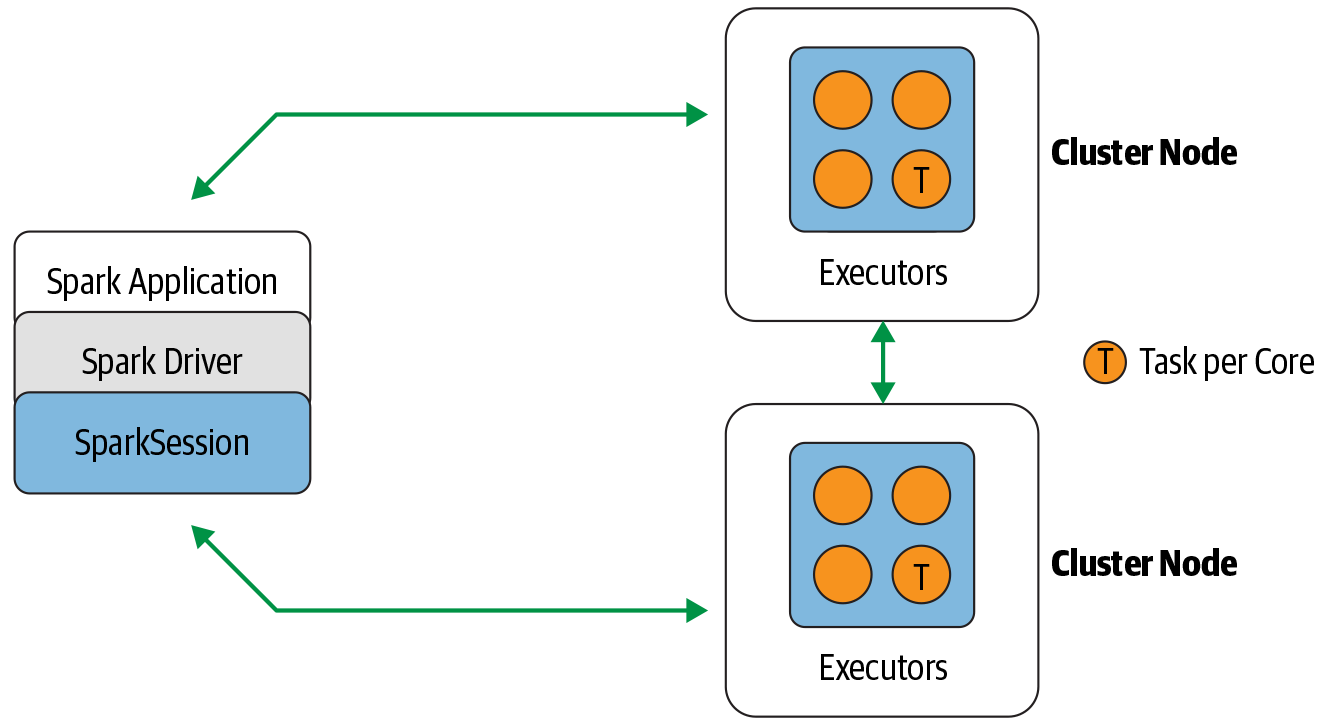
Each executor has 4 cores, each core gets a partition of data to work on
A Spark application is converted by the driver into one or more jobs during execution, with each job then transformed into a DAG as an execution plan. Nodes in the DAG are divided into different stages based on whether operations can be executed serially or in parallel, with stage boundaries typically determined by computational boundaries that require data transfer between executors. Each stage contains multiple tasks that are distributed across executors for execution, where each task corresponds to a core and processes a data partition.
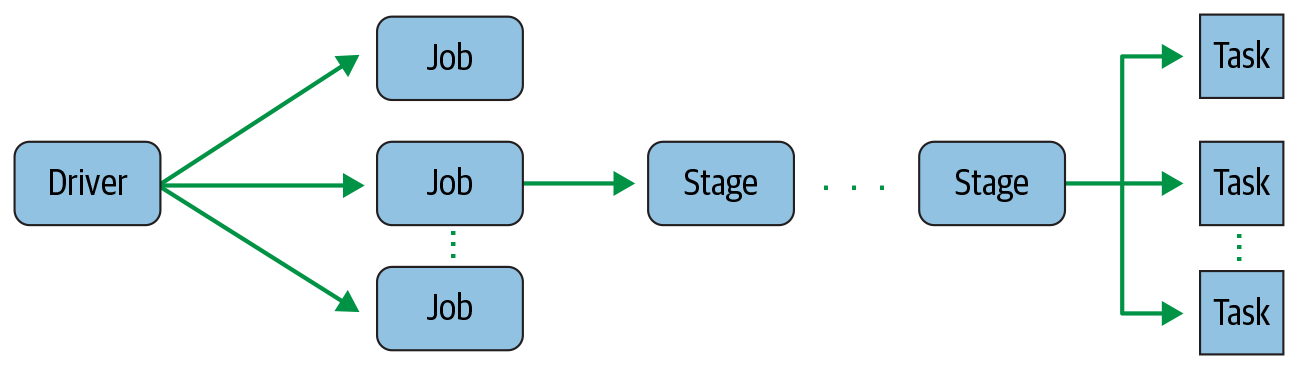
Spark Application DAG
Spark transformations fall into two categories based on their dependency patterns. Narrow dependencies occur when each output partition depends on data from only one input partition, making operations like filter() and contains() efficient to execute.
In contrast, wide dependencies require data shuffling across the cluster, as seen in operations like groupBy() or orderBy(), where multiple input partitions must be accessed to produce a single output partition, resulting in data being redistributed and persisted to storage.
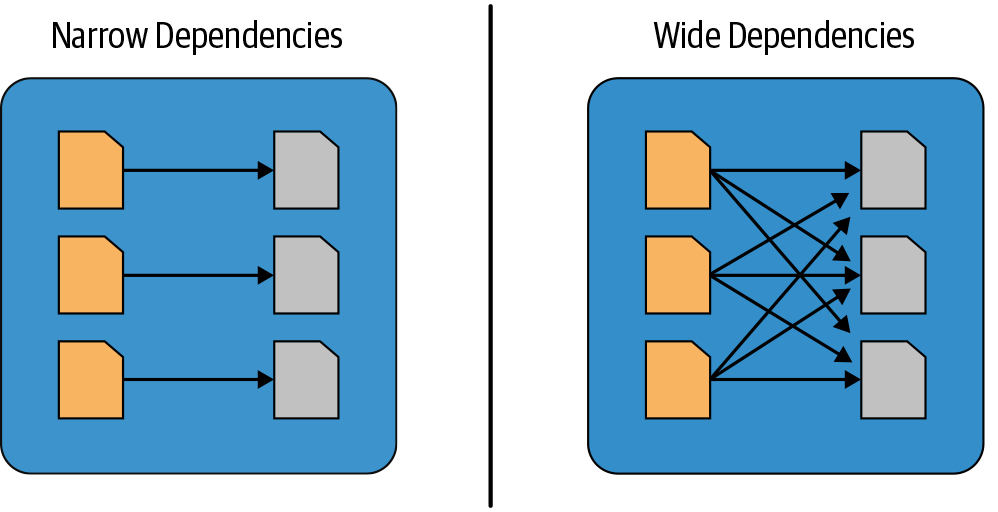
Narrow vs. Wide Dependencies