How Spark Works¶

Architecture Components¶
Driver Program¶
- The process running the
main()function of the application and creating theSparkContext
Cluster Manager¶
- An external service for acquiring resources on the cluster (e.g. standalone manager, YARN, Kubernetes)
Worker Node¶
- Any node that can run application code in the cluster
Executor¶
- A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors.
See Cluster Mode Overview for more details on the architecture components.
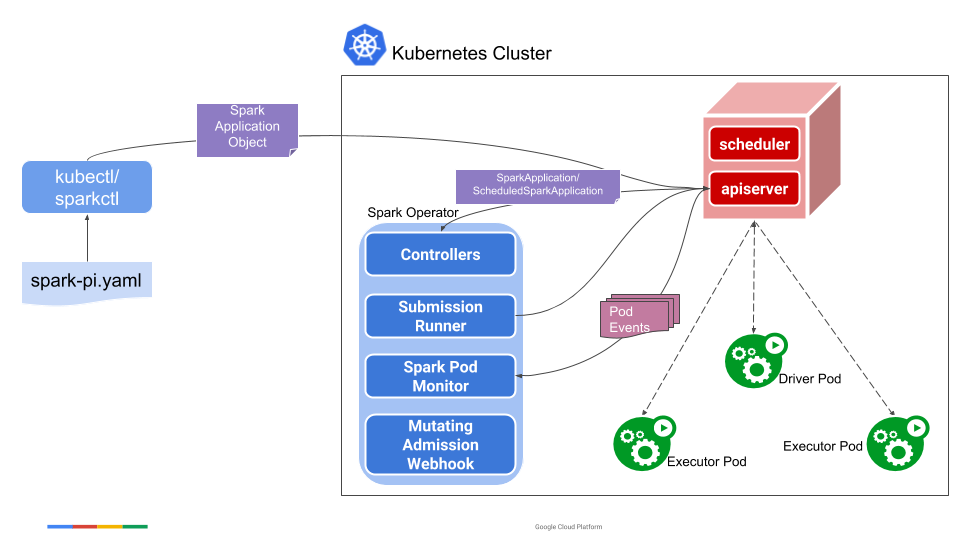
Kubeflow Spark Operator¶
When Spark 2.3 introduced Kubernetes as an official scheduler backend, it created challenges in managing Spark application lifecycles on Kubernetes. Unlike traditional workloads such as Deployments and StatefulSets, Spark applications required different approaches for submission, execution, and monitoring, making them difficult to manage idiomatically within Kubernetes environments.
The Kubeflow Spark Operator addresses these challenges by implementing the operator pattern to manage Spark applications declaratively. It allows users to specify Spark applications in YAML files without dealing with complex spark-submit processes, while providing native Kubernetes-style status tracking and monitoring capabilities that align with other Kubernetes workloads.
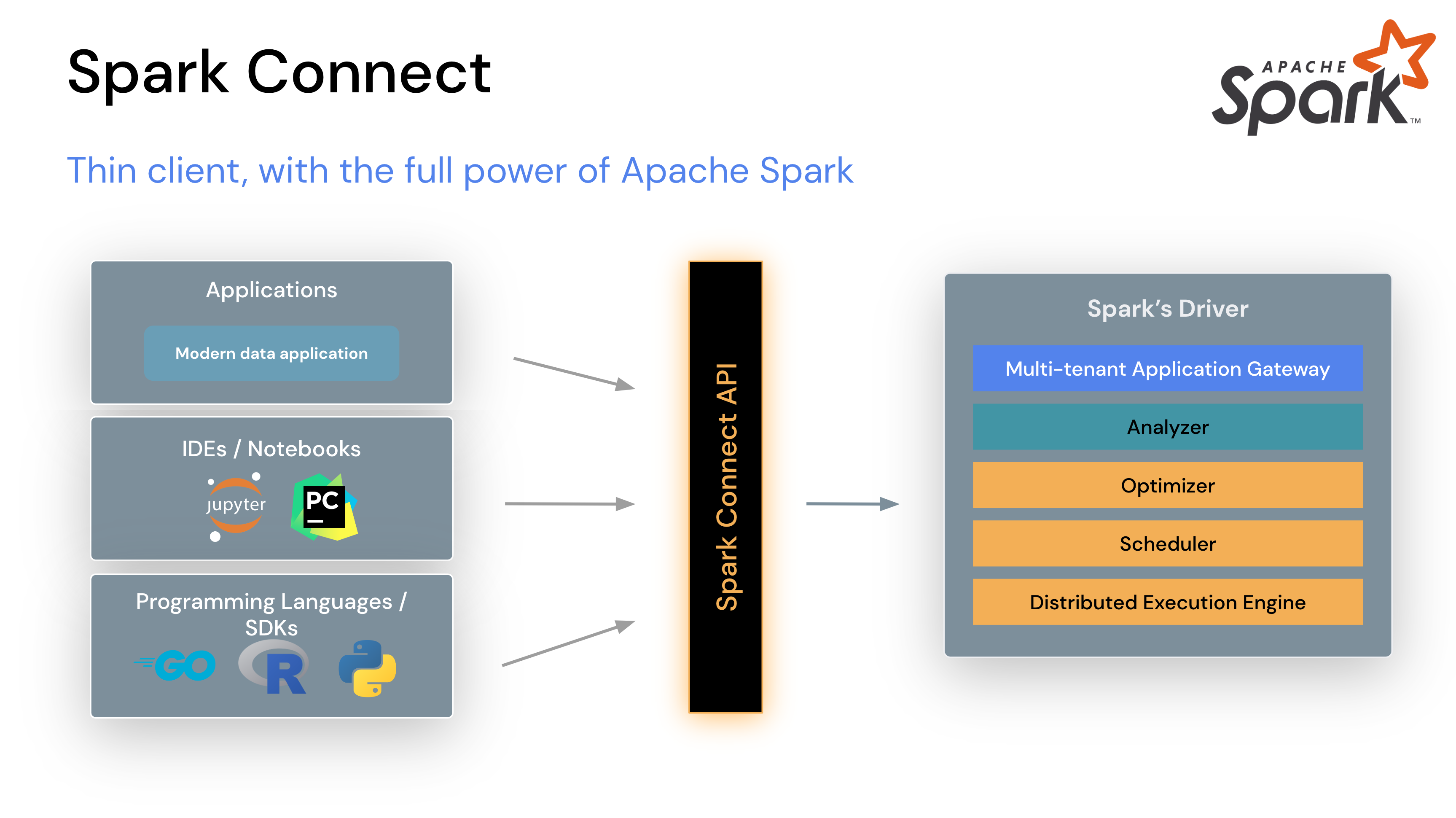
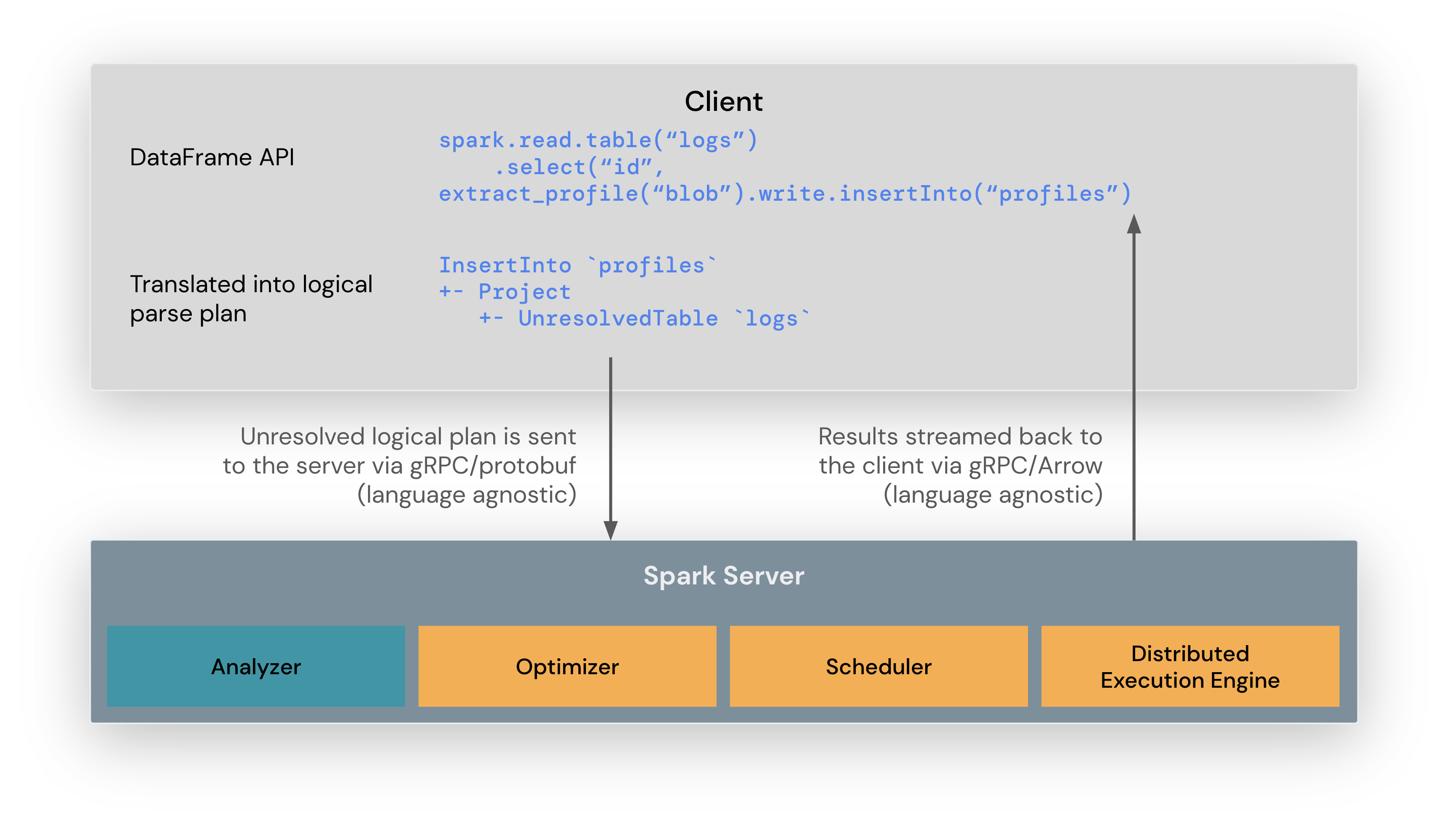
Spark Connect¶
Introduced in Spark 3.4, Spark Connect, decoupled client-server architecture that allows remote connectivity to Spark clusters using the DataFrame API and unresolved logical plans as the protocol