Apache Iceberg Best Practices in AWS¶
- Use Iceberg format version 2.
- Use the AWS Glue Data Catalog as your data catalog.
- Use the AWS Glue Data Catalog as lock manager.
- Use Zstandard (ZSTD) compression: you could configure
write.<file_type>.compression-codectozstdin your Iceberg table properties. It strikes a balance between GZIP and Snappy, and offers good read/write performance without compromising the compression ratio.
Optimizing Storage¶
- Enable S3 Intelligent-Tiering
-
Archive or delete historic snapshots
- Delete old snapshots:
expire_snapshots -
Set retention policies for specific snapshots: use Historical Tags to mark specific snapshots and define a retention policy for them.
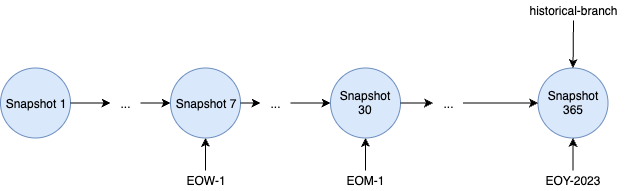 - Archive old snapshots:
- S3 Tags + S3 Life cycle rules
- Delete orphan files: remove_orphan_files -
- Archive old snapshots:
- S3 Tags + S3 Life cycle rules
- Delete orphan files: remove_orphan_files -spark.sql.catalog.my_catalog.s3.write.tags.my_key1=my_val1 spark.sql.catalog.my_catalog.s3.delete-enabled=false spark.sql.catalog.my_catalog.s3.delete.tags.my_key=to_archive spark.sql.catalog.my_catalog.s3.write.table-tag-enabled=true spark.sql.catalog.my_catalog.s3.write.namespace-tag-enabled=trueVACUUMstatement: equals toexpire_snapshots+remove_orphan_filesin Spark.
- Delete old snapshots: