Ch4 Optimizing the Performance of Apache Iceberg¶
Disclaimer: The content on this page is created purely from personal study and self-learning. It is intended as personal notes and reflections, not as professional advice. There is no commercial purpose, financial gain, or endorsement intended. While I strive for accuracy, the information may contain errors or outdated details. Please use the content at your own discretion and verify with authoritative sources when needed.
Tip
- Compaction
- Binpack
- Sorting
- Z-order
- Partitioning
- CoR vs. MoR
- Metric Collection
- Write Distribution Mode
- Datafile Bloom Filters
Compaction¶
In this scenario, we may have been streaming some data into our musicians table and noticed that a lot of small files were generated for rock bands, so instead of running compaction on the whole table, which can be time-consuming, we targeted just the data that was problematic. We also tell Spark to prioritize file groups that are larger in bytes and to keep files that are around 1 GB each with each file group of around 10 GB.
-- Rewrite Data Files CALL Procedure in SparkSQL
CALL catalog.system.rewrite_data_files(
table => 'musicians',
strategy => 'binpack',
where => 'genre = "rock"',
options => map(
'rewrite-job-order','bytes-asc',
'target-file-size-bytes','1073741824', -- 1GB
'max-file-group-size-bytes','10737418240' -- 10GB
)
)
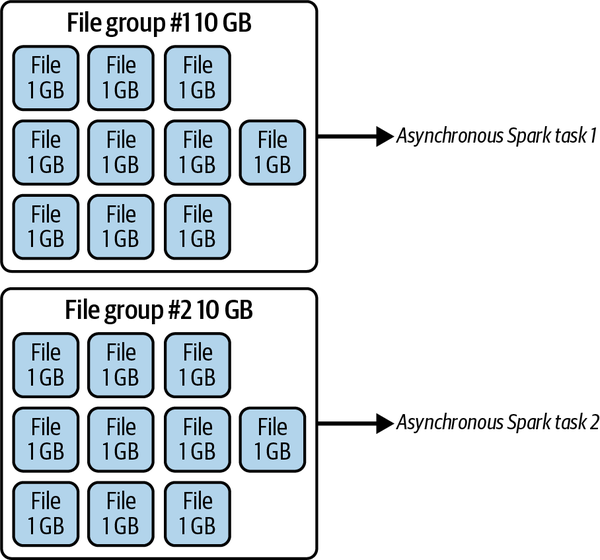
The result of having the max file group and max file size set to 10 GB and 1 GB, respectively
Sorting¶
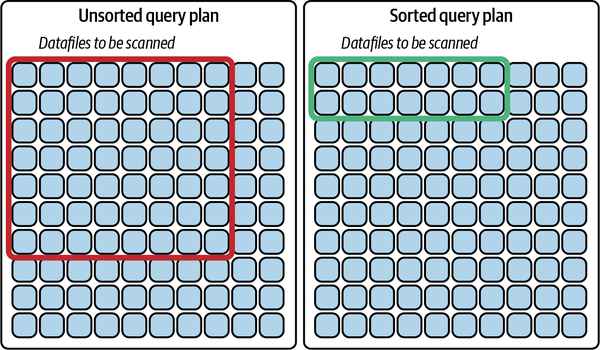
Sorted
After creating the table, you set the sort order of the table, which any engine that supports the property will use to sort the data before writing and will also be the default sort field when using the sort compaction strategy
CREATE TABLE catalog.nfl_teams
AS (SELECT * FROM non_iceberg_teams_table ORDER BY team);
ALTER TABLE catalog.nfl_teams WRITE ORDERED BY team;s
if you wanted to rewrite the entire dataset with all players sorted by team globally, you could run the following statement:
CALL catalog.system.rewrite_data_files(
table => 'nfl_teams',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST'
)
Z Order¶
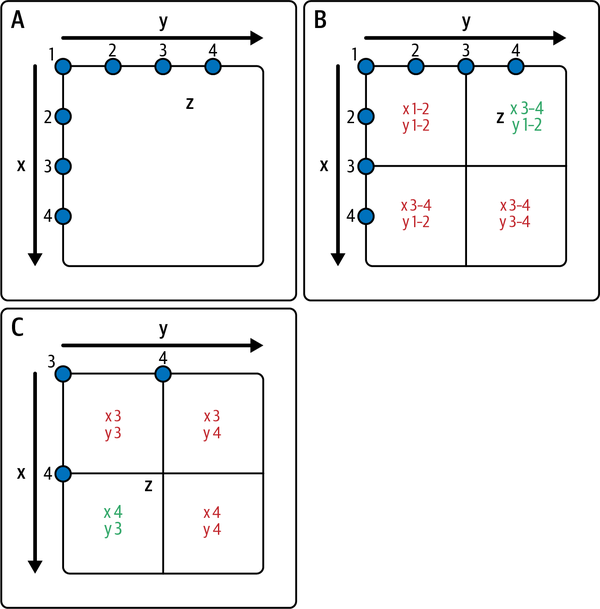
Z-order
CALL catalog.system.rewrite_data_files(
table => 'people',
strategy => 'sort',
sort_order => 'zorder(age,height)'
)
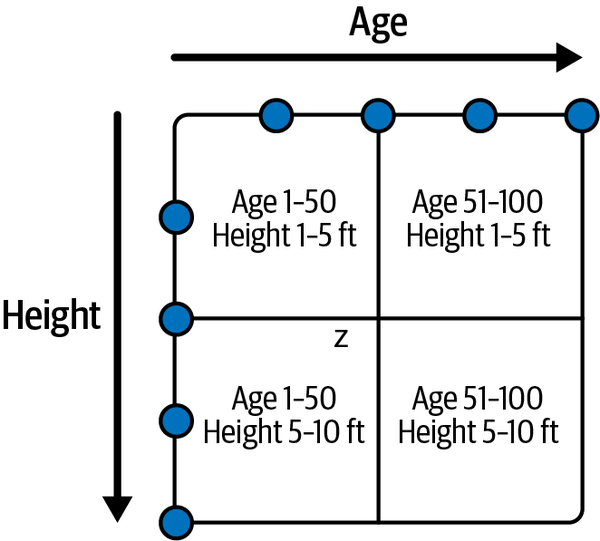
Z-ordering based on age and height
Partitioning¶
CoR vs. MoR¶
Metrics Collection¶
Write Distribution Mode¶
Write distribution mode requires an understanding of how massively parallel processing (MPP) systems handle writing files.
The write distribution is how the records to be written are distributed across these tasks. If no specific write distribution mode is set, data will be distributed arbitrarily. The first X number of records will go to the first task, the next X number to the next task, and so on.
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.distribution-mode'='hash',
'write.delete.distribution-mode'='none',
'write.update.distribution-mode'='range',
'write.merge.distribution-mode'='hash',
);
Datafile Bloom Filters¶
A bloom filter is a way of knowing whether a value possibly exists in a dataset.
Bloom filters are handy because they can help us avoid unnecessary data scans.
You can enable the writing of bloom filters for a particular column in your Parquet files (this can also be done for ORC files) via your table properties:
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.parquet.bloom-filter-enabled.column.col1'= true,
'write.parquet.bloom-filter-max-bytes'= 1048576
);
Then engines querying your data may take advantage of these bloom filters to help make reading the datafiles even faster by skipping datafiles where bloom filters clearly indicate that the data you need doesn't exist.