How It Works?¶
Key Modules and Their Roles¶
Ray Core is a powerful distributed computing framework that provides a small set of essential primitives (tasks, actors, and objects) for building and scaling distributed applications.1
On top of Ray Core, Ray provides different AI libraries for different ML workloads.
 Key Modules2
Key Modules2
| Module | Description | Details |
|---|---|---|
| Ray Data | Scalable datasets for ML | Ray Data provides distributed data processing optimized for machine learning and AI workloads. It efficiently streams data through data pipelines.2 |
| Ray Train | Distributed model training | Ray Train makes distributed model training simple. It abstracts away the complexity of setting up distributed training across popular frameworks like PyTorch and TensorFlow.2 |
| Ray Tune | Hyperparameter tuning at scale | Ray Tune is a library for hyperparameter tuning at any scale. It automatically finds the best hyperparameters for your models with efficient distributed search algorithms.2 |
| Ray Serve | Scalable model serving | Ray Serve provides scalable and programmable serving for ML models and business logic. Deploy models from any framework with production-ready performance.2 |
| Ray RLlib | Industry-grade reinforcement learning | RLlib is a reinforcement learning (RL) library that offers high performance implementations of popular RL algorithms and supports various training environments. RLlib offers high scalability and unified APIs for a variety of industry- and research applications.2 |
Architecture Components¶
 Ray Cluster3
Ray Cluster3
- Ray Cluster
-
A Ray cluster consists of a single head node and any number of connected worker nodes. Ray nodes are implemented as pods when running on Kubernetes.3
- Head Node
-
Every Ray cluster has one node which is designated as the head node of the cluster. The head node is identical to other worker nodes, except that it also runs singleton processes responsible for cluster management such as the autoscaler, GCS and the Ray driver processes which run Ray jobs.3
- Worker Node
-
Worker nodes do not run any head node management processes, and serve only to run user code in Ray tasks and actors.3
- Autoscaling
-
When the resource demands of the Ray workload exceed the current capacity of the cluster, the autoscaler will try to increase the number of worker nodes. When worker nodes sit idle, the autoscaler will remove worker nodes from the cluster.3
- Ray Jobs
-
A Ray job is a single application: it is the collection of Ray tasks, objects, and actors that originate from the same script. There are two ways to run a Ray job on a Ray cluster: (1) Ray Jobs API and (2) Run the driver script directly on the Ray cluster.3
 2 Ways of running Ray Jobs3
2 Ways of running Ray Jobs3
Core Concepts¶
- Tasks
-
Ray enables arbitrary functions to execute asynchronously on separate Python workers. These asynchronous Ray functions are called tasks. Ray enables tasks to specify their resource requirements in terms of CPUs, GPUs, and custom resources.7
- Actors
-
Actors extend the Ray API from functions (tasks) to classes. An actor is essentially a stateful worker (or a service).7
- Objects
-
Tasks and actors create objects and compute on objects. You can refer to these objects as remote objects. Ray caches remote objects in its distributed shared-memory object store.7
- Datasets
-
Datasetis the main user-facing Python API. It represents a distributed data collection and define data loading and processing operations. The Dataset API is lazy. Each Dataset consists of blocks.4 - Blocks
-
Each Dataset consists of blocks. A block is a contiguous subset of rows from a dataset, which are distributed across the cluster and processed independently in parallel.4
 Datasets and Blocks4
Datasets and Blocks4
- Training Function
-
The training function is a user-defined Python function that contains the end-to-end model training loop logic. When launching a distributed training job, each worker executes this training function.6
- Workers
-
Ray Train distributes model training compute to individual worker processes across the cluster. Each worker is a process that executes the training funciton.6
- Scaling Configuration
-
The
ScalingConfigis the mechanism for defining the scale of the training job. Two common parameters arenum_workersanduse_gpu.6 - Trainer
-
The Trainer ties the previous three concepts together to launch distributed training jobs.6
 Ray Tune Configuration5
Ray Tune Configuration5
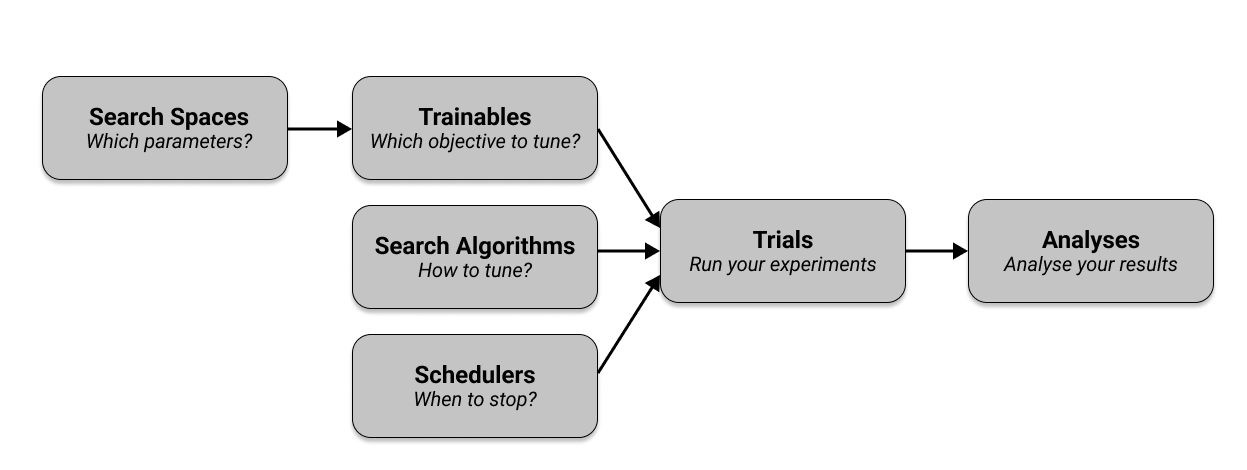
- Search Space
-
A search space defines valid values for your hyperparameters and can specify how these values are sampled. Tune offers various functions to define search spaces and sampling methods.58
- Search Algorithms
-
To optimize the hyperparameters of your training process, you use a Search Algorithm which suggests hyperparameter configurations. Tune has Search Algorithms that integrate with many popular optimization libraries, such as HyperOpt or Optuna.5 Tune automatically converts the provided search space into the search spaces the search algorithms and underlying libraries expect.
- Schedulers
-
In short, schedulers can stop, pause, or tweak the hyperparameters of running trials, potentially making your hyperparameter tuning process much faster. Tune includes distributed implementations of early stopping algorithms such as Median Stopping Rule, HyperBand, and ASHA. Tune also includes a distributed implementation of Population Based Training (PBT) and Population Based Bandits (PB2). When using schedulers, you may face compatibility issues5
- Trainables
-
In short, a Trainable is an object that you can pass into a Tune run. Ray Tune has two ways of defining a trainable, namely the Function API and the Class API. The Function API is generally recommended.5
- Trials
-
You use
Tuner.fit()to execute and manage hyperparameter tuning and generate your trials. The Tuner.fit() function also provides many features such as logging, checkpointing, and early stopping.5 - Analyses
-
Tuner.fit()returns anResultGridobject which has methods you can use for analyzing your training.5
- Deployment
-
A deployment contains business logic or an ML model to handle incoming requests and can be scaled up to run across a Ray cluster. At runtime, a deployment consists of a number of replicas, which are individual copies of the class or function that are started in separate Ray Actors (processes).9
- Application
-
An application is the unit of upgrade in a Ray Serve cluster. An application consists of one or more deployments. One of these deployments is considered the “ingress” deployment, which handles all inbound traffic.9
- DeploymentHandle (composing deployments)
-
Ray Serve enables flexible model composition and scaling by allowing multiple independent deployments to call into each other.9
- Ingress deployment (HTTP handling)
-
The ingress deployment defines the HTTP handling logic for the application.9
Behind the Scenes¶
Ray Data uses a two-phase planning process to execute operations efficiently:4
- Logical plans consist of logical operators that describe what operation to perform.
- Physical plans consist of physical operators that describe how to execute the operation.
The building blocks of these plans are operators:4
- Logical plans consist of logical operators that describe what operation to perform.
- Physical plans consist of physical operators that describe how to execute the operation.
Ray Data uses a streaming execution model to efficiently process large datasets. It can process data in a streaming fashion through a pipeline of operations.4
 Streaming Topology4
Streaming Topology4
In the streaming execution model, operators are connected in a pipeline, with each operator’s output queue feeding directly into the input queue of the next downstream operator. This creates an efficient flow of data through the execution plan.4
Calling the Trainer.fit() method executes the training job by6:
- Launching workers as defined by the
scaling_config. - Setting up the framework's distributed environment on all workers.
- Running the training function on all workers.
Calling the Trainer.fit() method executes the tuning job by:
- The driver process launches and schedules trials across the Ray cluster based on the search space and resources defined.
- Each trial runs as a Ray task or actor on worker nodes, executing training functions in parallel.
- Results are collected, and once all trials finish (or meet stop criteria), tuner.fit() returns the best configs and metrics.